Abstract
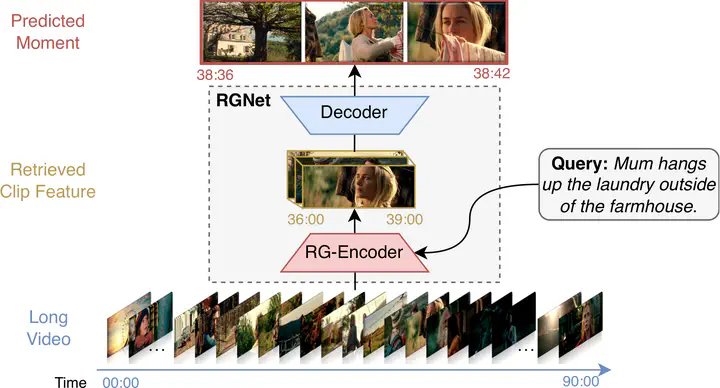
We present a novel end-to-end method for long-form video temporal grounding to locate specific moments described by natural language queries. Prior long-video methods for this task typically contain two stages, proposal selection and grounding regression. However, the proposal selection of these methods is disjoint from the grounding network and is not trained end-to-end, which limits the effectiveness of these methods. Moreover, these methods operate uniformly over the entire temporal window, which is suboptimal given redundant and irrelevant features in long videos. In contrast to these prior approaches, we introduce RGNet, a unified network designed for jointly selecting proposals from hour-long videos and locating moments specified by natural language queries within them. To achieve this, we redefine proposal selection as a video-text retrieval task, i.e., retrieving the correct candidate videos given a text query. The core component of RGNet is a unified cross-modal RG-Encoder that bridges the two stages with shared features and mutual optimization. The encoder strategically focuses on relevant time frames using a sparse sampling technique. RGNet outperforms previous methods, demonstrating state-of-the-art performance on long video temporal grounding datasets MAD and Ego4D.
Tanveer Hannan
Solution Architect | PhD Candidate of AI
My research interests include computer vision, video understanding, and multi-modal deep learning..